Pulmonary Nodule Segmentation
The Purpose
Our purpose was given the CT scans of a lung we want to predict the location(s) of the nodules in the lung. Currently, identification and classification of lung nodules are done by experienced annotators. We aim to build a model that can segment a lung CT scan and predict the existence of a nodule.
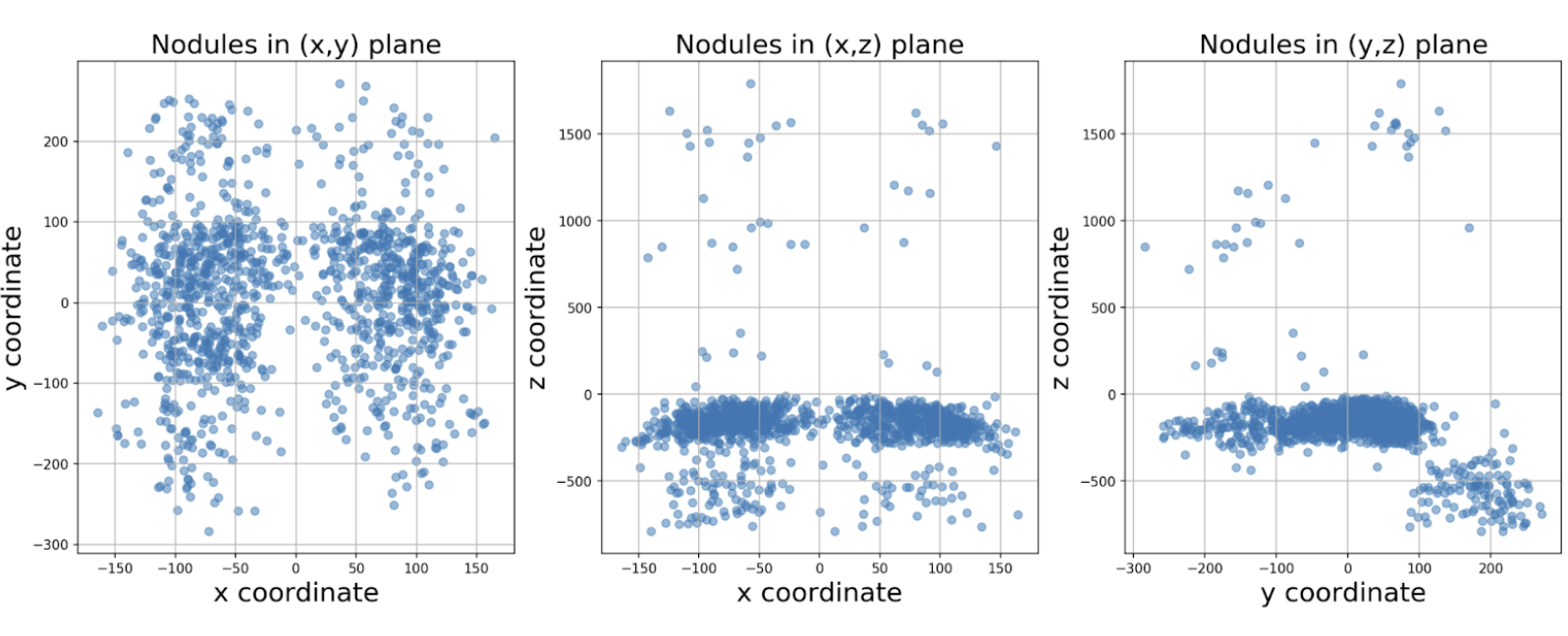
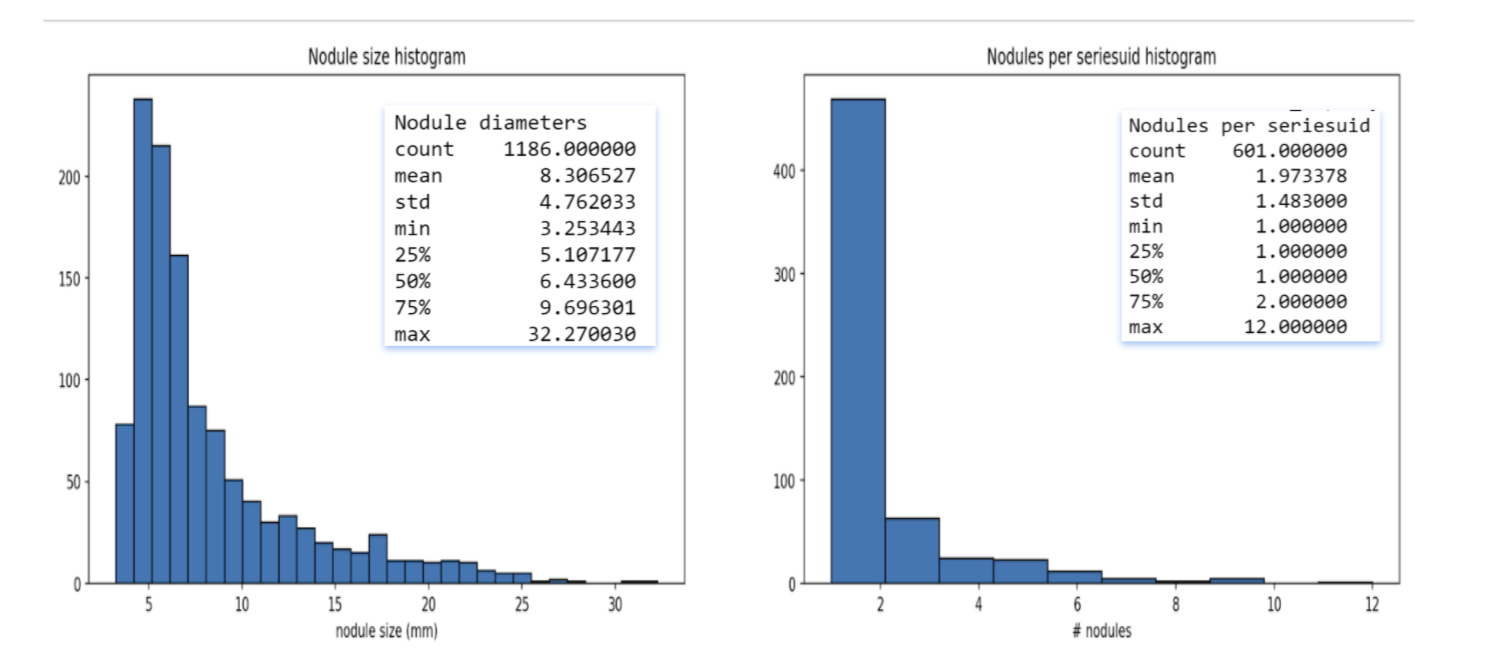
The dataset we are using is from a public dataset called Lung Nodule Analaysis 2016 (LUNA-16). It has a total of 888 CT scans. There are a total of 1186 nodules for 601 of those CT scans. The annotations file contatins the x,y,z coordinates of each nodule with a size >= 3mm and its corresponding CT scan. The data files take up approximately 115 GB of data.
The Quest
- Locate the nodules to use as input
- Using the annotated data, we know for each CT Scan where the nodules in that image are.
- Identify the nodules by matching the annotated locations given by the experts to the images.
- A subset of these images (training set) will be processed so that a nodule mask will be generated for each nodule.
- The nodule masks will be inputted into the model.
- Classify each pixel in image (Semantic Segmentation)
- Input CT scans into the model so the model can be trained.
- Models will classify each pixel in the image and label it as a nodule or not.
- Once model is built we can use it to predict the location of lung nodules in other CT scans of lungs (testing set).
The Solution
Semantic Segmentation

Understanding our Dataset
Preprocessing Images
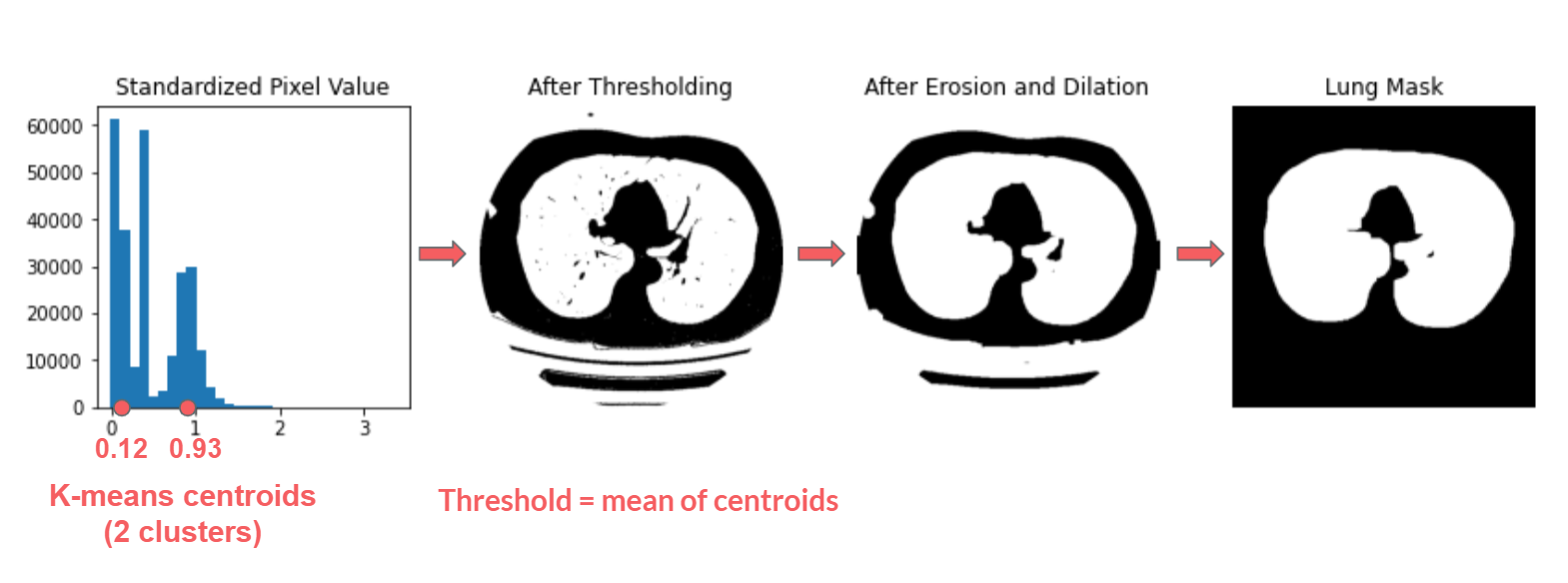
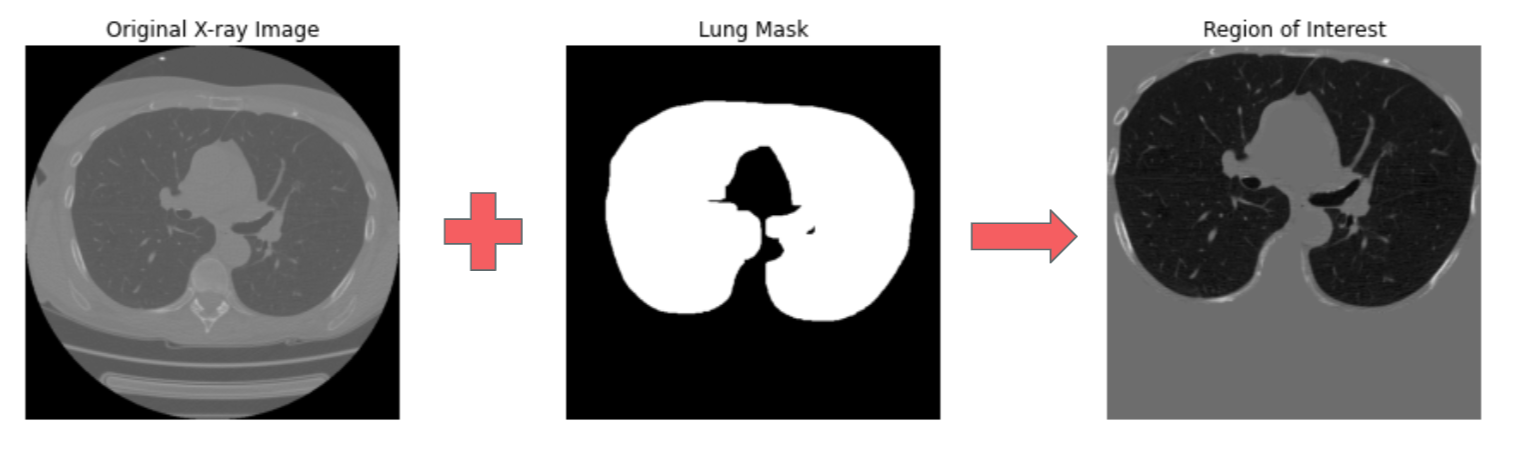
Modeling and Training
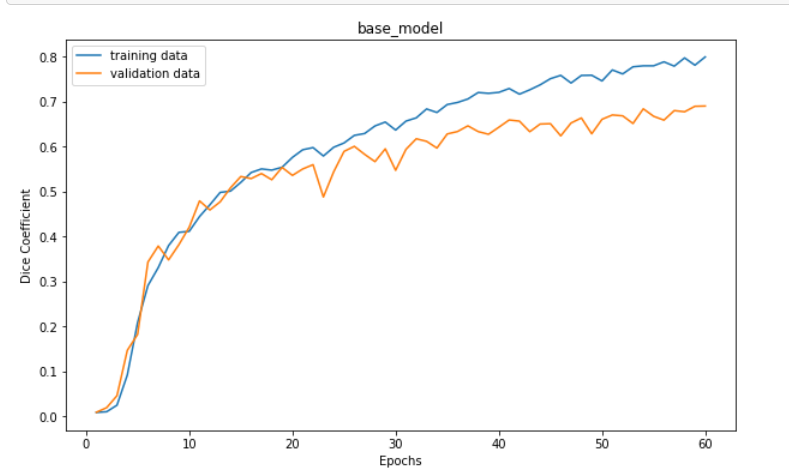
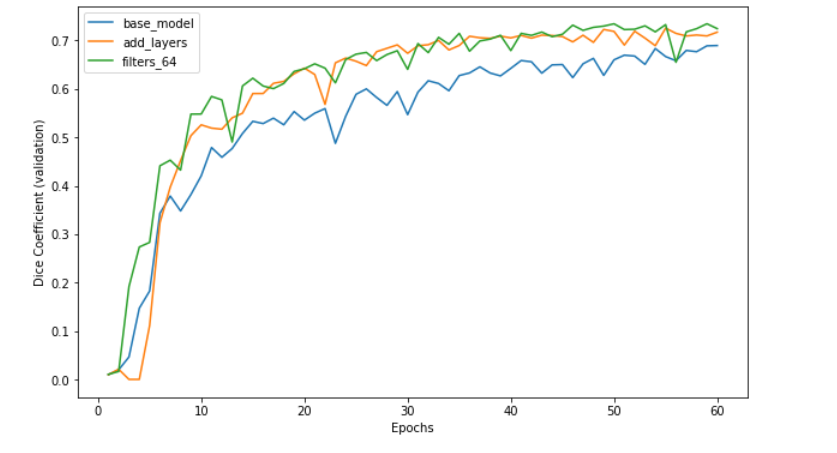
We used a "U-Net" architecture for our Convolutional Neural Network (CNN) which consists of 2 branches, contracting and expanding.
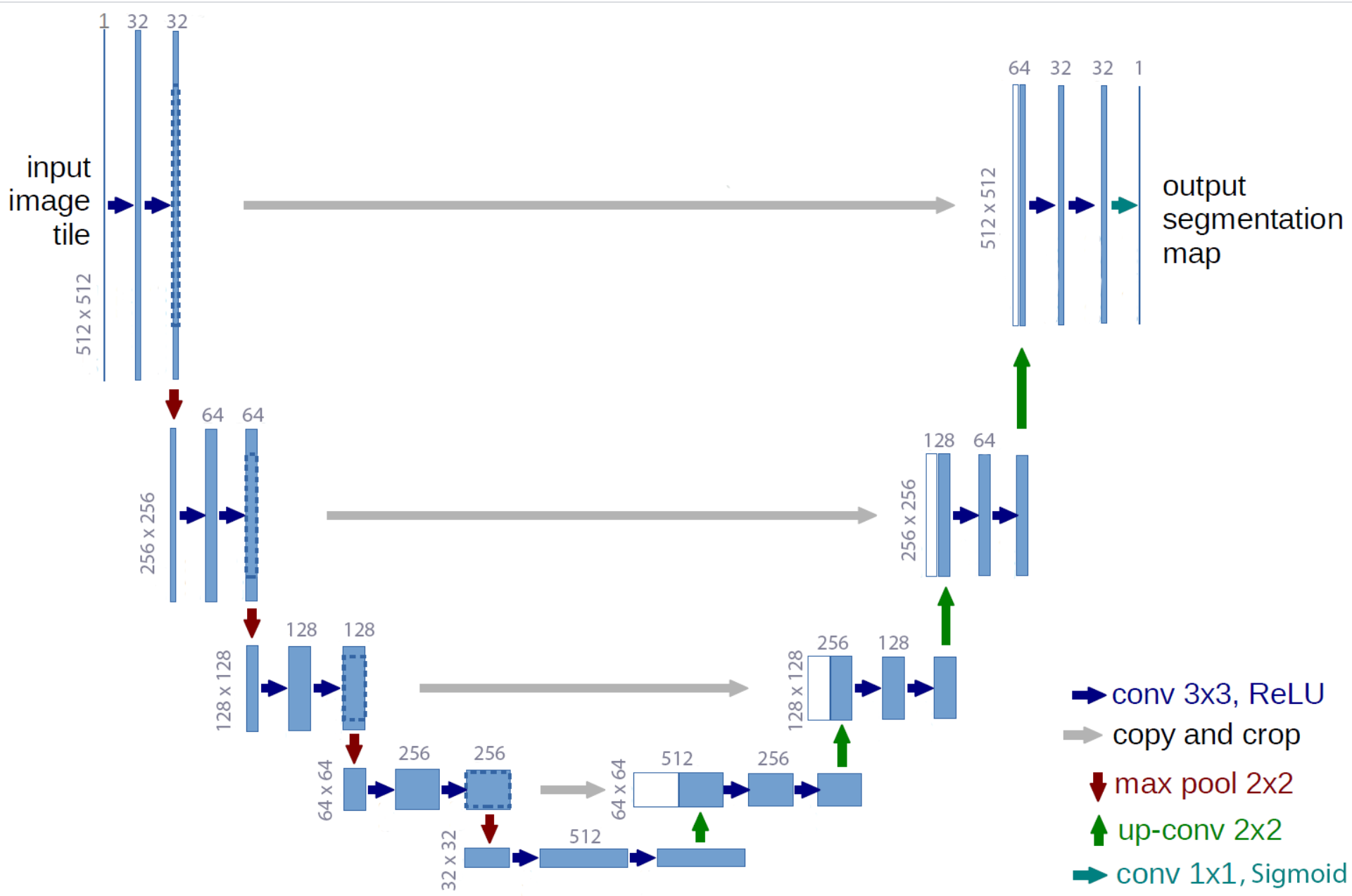

We used tensorflow_cloud api to train the model in Google AI Platform.
The Impact